作为一位师范类院校的教师,笔者认为做一名优秀的教师与做科学研究并不矛盾.不断地总结教学经验,与学生交流互动也可以在其中发现值得研究的问题,通过深入研究又促进自己的教学水平的提高.笔者从次序统计量的分布来论述,通过最基本的概念探究、纵横向扩展掌握、相关文献的探究等方面谈对高校教师教学的几点思考.
一、对知识点的深入掌握(一)对定义的讲解定义、概念的讲解是授课时的难点、重点.由于教材中对定义、概念的叙述都是十分精练的语言,如何让学生正确地理解就需要授课教师详细、精准地讲解.
定义:设x1,x2,…,xn是取自总体X的样本,x(i)称为该样本的第i个次序统计量,x(i)是将样本观测值由小到大排列后得到的第i个观测值.[1]
这是笔者教学时常用的教材中的定义.该书中在统计部分对随机变量与随机变量的取值都统一用小写字母表示,直接论述定义,学生一般都理解得不透彻.应当说明的是,当来自总体X的样本X1,X2,…,Xn的取值为x1,x2,…,xn时,将观测值由小到大的次序重新排列为x(1)≤x(2)≤…≤x(n),定义X(i)的取值为x(i),则x(1),x(2),…,x(n)为样本X1,X2,…,Xn的次序统计量.如此便很清晰地表示出X(i)的统计量的性质,它是样本的函数,随着样本取值的不同而不同,并且也将其可能取得相同值的情况说明了.
(二)按一贯思维模式把握知识点次序统计量的抽样分布常用在连续总体上,对连续型我们一般只需要求得次序统计量的密度函数即可,但是在概率论部分已形成思维定式,我们习惯于对一个新的问题去研究其分布函数,分别分为离散型与连续型时去研究其分布律与概率密度函数.因此,尽管教科书以及大部分的教辅书仅对连续型随机变量的抽样分布进行叙述,学生受一贯思维模式的影响是很容易提出次序统计量在其他情形时抽样分布的求解情况的疑问的,教师仍应将离散型的情况研究透彻.
1.分布函数的表示.
定理1 设总体X的分布函数为F(x),则第k个次序统计量X(k)的分布函数为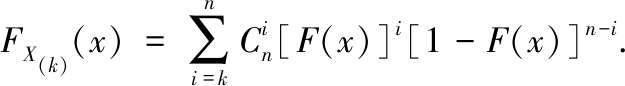
证明 对FX(k)(x)=P(X(k)≤x),第k个次序统计量小于等于x,即事件X(k)≤x等价于前k-1个次序统计量小于等于x,后n-k个次序统计量有可能大于x也有可能小于等于x.事件X(k)≤x表示X(i)≤x当i=k+1,k+2,…,n都有可能发生,我们将这一事件分割成为互不相容的n-k+1个事件,X(k)≤x<X(k+1),
X(k+1)≤x<X(k+2),…,X(n-1)≤x<X(n),X(n)≤x.
而事件X(k)≤x<X(k+1)表示随机变量X1,X2,…,Xn中有k个小于等于x,有n-k个大于x,因此,
(1.2.1)
2.离散型的表示.
定理2 设随机变量X是一个取值可按大小顺序排列的离散型随机变量,分布律为 设
设 当i1<i2,则
当i1<i2,则
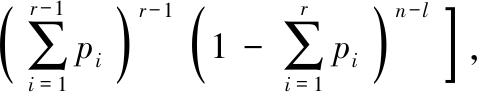
j表示子样值顺序序列中第一个等于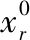 的值的序号,l表示最后一个等于的值的序号[2].
的值的序号,l表示最后一个等于的值的序号[2].
对课外知识的补充,这个结论的表达式比较烦琐,教师可以通过最简单的例子给学生讲解,说明结论的正确性.例如,先写出最小次序统计量的分布律:
(1.2.2)
试求服从(0-1)分布的随机变量X,分布律为P(X=k)=pk(1-p)1-k,k=0,1,当样本容量为2时,X(1)=1的概率.
解法一:直观地看,显然仅在样本为1,1时,X(1)=1,因此,P(X(1)=1)=p2.
解法二:由(1.2.2)式得
3.连续型的表示
求当X为连续型时第k次序统计量的概率密度函数,可以通过对1.2.1式求导得到,也可以按照[1]中的方法计算,并且可以通过比较说明[1]中的方法在求多个次序统计量的分布时,更容易讲解一些,
定理3 对来自总体X(密度函数为p(x),分布函数为F(x))的简单随机样本X1,X2,…,Xn,X(1),X(2),…,X(n)为次序统计量,第k个次序统计量X(k)的概率密度函数为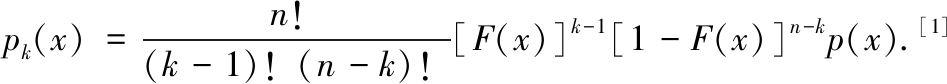
二、与其他知识点联系思考整个知识体系犹如一张巨大的网,无论哪一个知识点都会与其他若干知识点有紧密联系.对同一门课程而言,通过将一个知识点与其他章节概念联系,相互渗透、容纳,不仅有利于系统地将整本书的概念体系融会贯通,还可以做到创新,对教学与科研都大有裨益,例如,我们可以将次序统计量抽样分布的证明与多维随机变量的分布中最大值分布联系;在次序统计量例题讲解中可以与随机变量的数字特征联系求解等.以下笔者将次序统计量与分布拟合检验部分内容联合起来思考.
笔者以[1]中“分布拟和检验”这一章节中的一道例题为例.
例:某气象站收集了44个独立的年降雨量数据,资料如下(已排序):
520 556 561 616 635 669 686 692 704
707 711 713 714 719 727 735 740 744
745 750 776 777 786 786 791 794 821
822 826 834 837 851 862 837 879 889
900 904 922 926 952 963 1056 1074
假设年降雨量服从正态分布,首先用最大似然估计的方法,求得总体均值与方差的估计分别为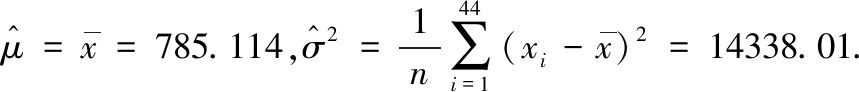 将这44个数据分为六组,组距为100,得出频数频率分布表如表2.1
将这44个数据分为六组,组距为100,得出频数频率分布表如表2.1
表2.1 频数频率分布表

在2.1频数频率分布表最后一列是通过SPSS转换菜单下计算变量选项中的Pdf.Binom函数计算出的二项分布的概率值 其中
其中 为分组区间的上限值,k为每组中的最大次序统计量的序号.该列数据可以作为在数据不完全时对原数据是否服从正态分布的一个粗略估计,可利用分组数据的中位数作为均值的估计量,仅计算一两个数值,根据实际推断原则,认为小概率事件不会发生.在表2.1的最后这一列数据中我们看到概率均大于10%,因此,可认为这些数据服从正态分布.
为分组区间的上限值,k为每组中的最大次序统计量的序号.该列数据可以作为在数据不完全时对原数据是否服从正态分布的一个粗略估计,可利用分组数据的中位数作为均值的估计量,仅计算一两个数值,根据实际推断原则,认为小概率事件不会发生.在表2.1的最后这一列数据中我们看到概率均大于10%,因此,可认为这些数据服从正态分布.
三、对相关文献的分析(一)研究知识点在当下的最新应用数理统计从其理论建立起来,就一直为现代各科学研究领域服务,其应用范围非常广泛,结合其应用范围又分为社会统计学、卫生统计学、司法统计学、人口统计学、管理统计学、环境统计学等等.如今教材中的知识点已经被前人完善,其基本理论定义定理的提出及证明是相当完备的,但教师可在对相关理论深入研究后,查阅与该知识点相关的最新文献,了解其发展动态,有助于对当下最前沿科研成果的了解,与自己研究方向相关的课题更值得深入探讨,从而得出新的见解.而在课堂教学中应该注意的是,若谈及其在某一方面的应用,就应当对这一方面有所了解,能够将其应用的背景、目的、方法等解释清楚.
(二)研究分析他人的成果在对现存文献的研究中,应避免“拿来主义”,对已成铅字的文献,若不假思索地引用,那么自己的研究基石也不一定稳固.例如,求第k个次序统计量X(k)的概率密度,为将随机变量等值的情况考虑进去,对考虑第k个次序统计量X(k)落入无穷小区间(x,x+Δx]内这一事件,等价于“容量n的样本中有k-1个分量小于或等于x+Δx,1个分量落在(x,x+Δx],余下的n-k个分量均不小于x”.以Fk(x)记X(k)的分布函数,F(x)记总体X的分布函数,那么X(k)落入无穷小区间(x,x+Δx]内这一事件的概率为
(3.2)
这一结论是[3]证明过程中的中间步骤,是与教科书[1]中不同之处,二者最终得出的X(k)的概率密度的表达式是一致的.3.2式的得出还未用到随机变量的连续型性质,为验证此式的正确性,笔者以(0-1)分布为例.
设总体X服从(0-1)分布,P(X=0)=1-p,0≤p≤1,F(1)=1,考虑第k个次序统计量X(k)落入(1-Δx,1]的概率,利用3.2式

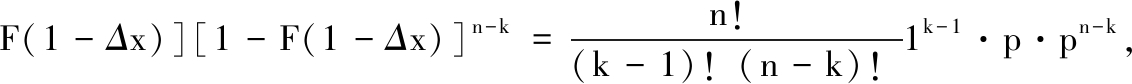
代入n=2,k=1,得到Fk(1)-Fk(1-Δx)=2·p2,当 时,上式大于1.由此看出3.2式的正确性是值得质疑的.[3]未考虑将随机变量等值的情况,在划分随机变量落入的区间总和大于随机变量的实际取值范围,而[1]中的证明因随机变量的连续性未考虑随机变量重值的情形,但在实际统计数据的处理中,往往使用的都是分组数据,同一组数据的取值是以组中值代替的,这就不可避免地出现了重值的情况.笔者认为在X(k)取到重值时,其概率密度应修正为
时,上式大于1.由此看出3.2式的正确性是值得质疑的.[3]未考虑将随机变量等值的情况,在划分随机变量落入的区间总和大于随机变量的实际取值范围,而[1]中的证明因随机变量的连续性未考虑随机变量重值的情形,但在实际统计数据的处理中,往往使用的都是分组数据,同一组数据的取值是以组中值代替的,这就不可避免地出现了重值的情况.笔者认为在X(k)取到重值时,其概率密度应修正为
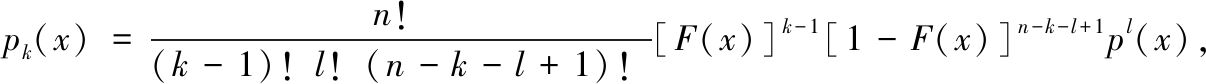
其中l为X(k)的重数.
四、余 论教师在教学中,应该不断地提高自己对所授课程的认识.本文实际是从最基本的理念谈起,正如许多前辈所说,真正吃透一门课,要先将教材变厚再变薄,这是过去许多教师做到的事,如今教师正在做的事,更是以后的教师要一直做的事.这是能够教授这门课的基础,也是能够进行相关研究的前提.但是在科技信息高速腾飞的时代,这件简单基础的事往往被忽视,很容易就能读到最新科研文献,于是将自己的研究架在前人研究成果之上,而缺乏对其基础理论的掌握与认识,结果像空中楼阁一般经不起推敲,大量文献也因此存在对基本理论的滥用、误用的现象[4].
笔者认为,教师对自己所教的课程、研究的方向的每一个知识点的精雕细琢,不仅有利于教学、科研中对该知识点的研究品味,更有利于对整个知识体系的融会贯通.尤其对数学类的课程,此类的教学研究与教学反思必不可少.
【参考文献】
[1]茆诗松,程依明,濮晓龙.概率论与数理统计教程[M].北京:高等教育出版社,2004:259-263.
[2]夏圣亭.离散型随机变量的次序统计量的分布[J].工科数学,2000,16(2):99-101.
[3]杨桂元.次序统计量的抽样分布[J].数学理论与应用,2005(3):104-106.
[4]李健,祁国鹰,王锡群.从体育统计误用透视高校体育统计[J].体育科技,2009(1):79-81.

